在k8s的使用场景中,容器不是仅仅能运行就算ok,往往还需要进行容器的内核参数优化和应用程序参数的调优,如在高并发的业务场景下,运行一个java程序,我们不仅需要对其JVM参数进行调优,而且需要对其所在的容器进行内核参数优化,这篇文章主要通过一次容器丢包事件介绍容器中内核参数优化的方法。
线上业务反馈接口偶发性返回502状态码,从请求日志和监控系统看,有好几个微服务的接口都有出现,期间容器资源使用率平稳并无异常,而502的发生主要聚焦在业务高峰阶段,所以暂时排除了是微服务性能问题,优先尝试通过压测的方式在非生产环境复现。
为了方便复现,将pod设置为单副本,链路大致如下:
client --> ingress --> service --> pod
排查与分析过程
1、使用ab压测,设置请求数50000,并发数200,未能复现;
2、尝试增加并发数至500时,502的场景复现了,起初怀疑是conntrack table满了,但通过dmesg和conntrack -S查看并无异常;
3、经过一顿排查,最终通过下面的指令定位到容器的半连接队列满了,导致请求被丢弃
netstat -st | egrep -i "drop|reject|overflowed|listen|filter|TCPSYNChallenge"
知识点插播
1、排查与分析过程中用到的netstat指令的作用是什么?
打印包含上述关键词相关的 TCP 统计信息,帮助我们快速定位和分析网络问题,如丢包、连接被拒绝、缓冲区溢出、监听端口状态、包过滤情况以及 TCP SYN 挑战等。
- drop:表示丢弃的数据包,可能由于网络拥塞或错误配置导致。
- reject:表示被拒绝的数据包,通常是因为防火墙规则或访问控制列表(ACL)拒绝了这些连接。
- overflowed:表示溢出的数据包,可能是由于缓冲区或队列满了,导致无法处理更多的数据包。
- listen:表示监听的端口和连接,通常用于显示服务器正在监听的端口和等待连接的数量。
- filter:表示过滤的统计信息,通常与防火墙或包过滤器相关。
- TCPSYNChallenge:表示 TCP SYN 挑战包的统计信息,用于防止 SYN flood 攻击的一种保护机制。
2、什么是半连接队列/长连接队列?二者之间的区别又在哪?
如图所示,一个完整的TCP连接的建立,会经历一次3次握手,两个状态:SYN_REVD、ESTABELLISHED,而操作系统中用来存放他们的,我们称之为队列,即
半连接队列:存放SYN的队列
全连接队列:存放已经完成连接的队列
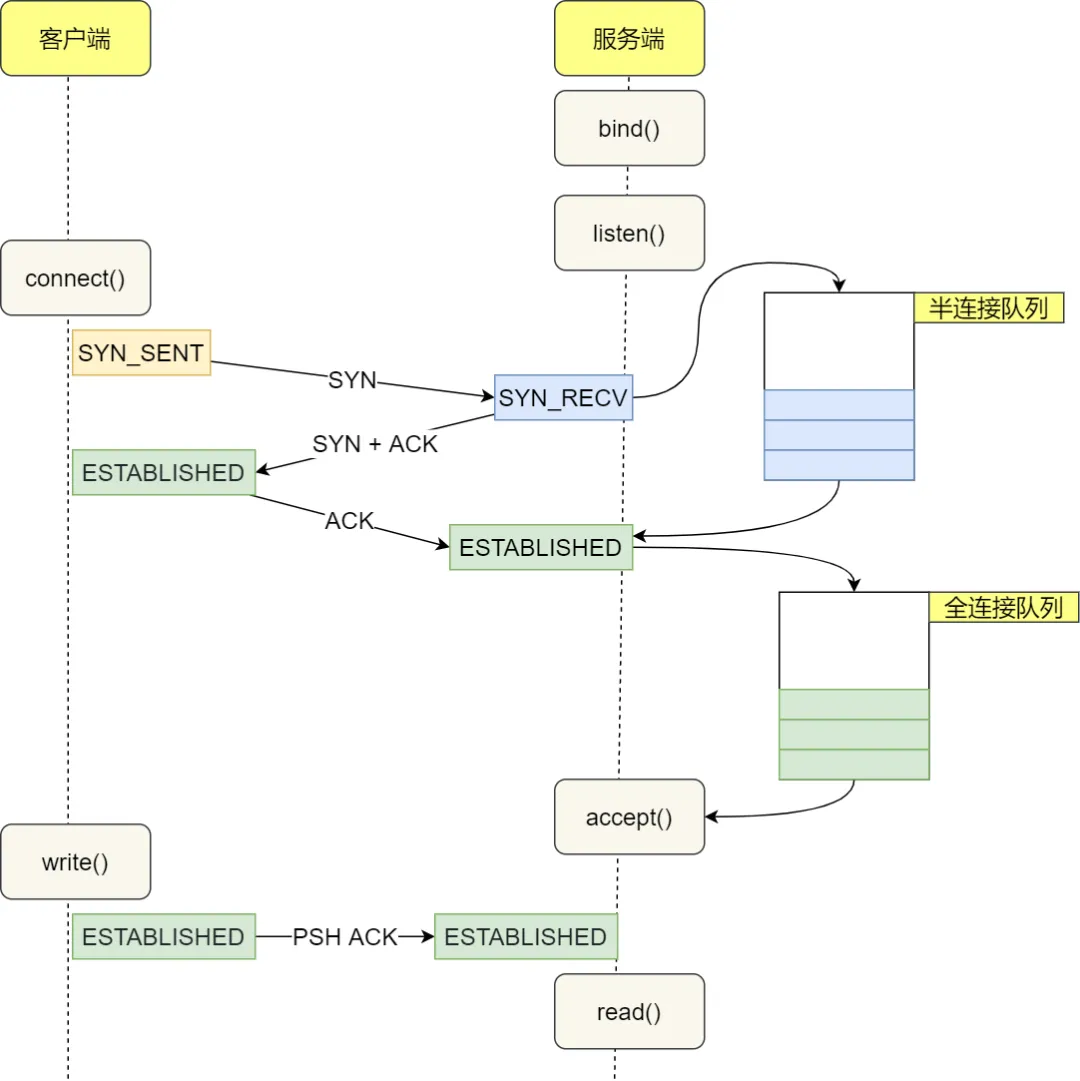
3、半连接队列/长连接队列的长度跟哪些内核参数有关?
半连接队列:长度为net.core.somaxconn、tcp_max_syn_backlog的最小值
全连接队列:长度为net.core.somaxconn的值。
其中tcp_max_syn_backlog的值并未定义,而net.core.somaxconn的默认值为128,一般我们可以调整net.core.somaxconn的值来增加队列的长度。
问题优化
在Pod中并不能直接通过sysctl修改内核参数,所以我们使用init容器进行修改,在yaml中加入如下内容,将连接队列长度调整为2048,在优化后502状态码明显减少。
spec: initContainers: - name: init-sysctl image: busybox command: - sh - '-c' - echo 2048 > /proc/sys/net/core/somaxconn resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File imagePullPolicy: Always securityContext: privileged: true综上所述,容器的性能并不能简单的交给弹性伸缩,一味地增加资源有时候并不能解决问题,反而会造成资源浪费,所以容器的性能和应用程序的性能我们都应该去关注和优化!