很多公司听说可观测性好,就要上马可观测性项目,自研/采购,各种投入,结果发现效果很差,业务不认可,最终一地鸡毛。其实凡事总有个过程和时机问题,在落地可观测性之前,我建议你先看看你们的监控做好了没有,监控的投入产出比高,也是可观测性的数据基础之一。
我们公司就是提供监控+可观测性的产品和解决方案,在这里讲让大家慎重落地可观测性,其实是对我们不利的,不过作为乙方,我们更希望真正解决甲方的问题,共同成事,而不是贩卖焦虑,让甲方投入大量资源,最终效果却很差。
可观测性如果建设的好,对故障定位、梳理架构、知识沉淀等各方面都有作用。目前,大家建设可观测性,最核心的诉求就是解决故障定位的问题,但是兄弟们,定位故障之前,你得先发现故障啊,而且尽量是靠技术手段发现故障,而非靠客户投诉!而发现故障,就是靠监控了!
你可能会想,监控还不简单,Zabbix、Prometheus、Nightingale 很容易就搞定了。嗯,如果说仅仅只是把这些工具装上,那确实简单,但你要思考两个问题:
- 覆盖完备性:是否所有该采集的数据都采集了,该监控的都监控了,该配置的告警规则都无遗漏且合理?
- 能力完备性:数据采集、存储,告警规则管理,事件分发,收敛降噪,告警自愈,都有完备的能力吗?
不是说可观测性不能搞,而是先搞监控,ROI 更高,如果上面两个问题,你觉得都搞挺好了,那你再考虑可观测性为时不晚。
覆盖完备性
从监控目标类别划分,监控分为如下方向:
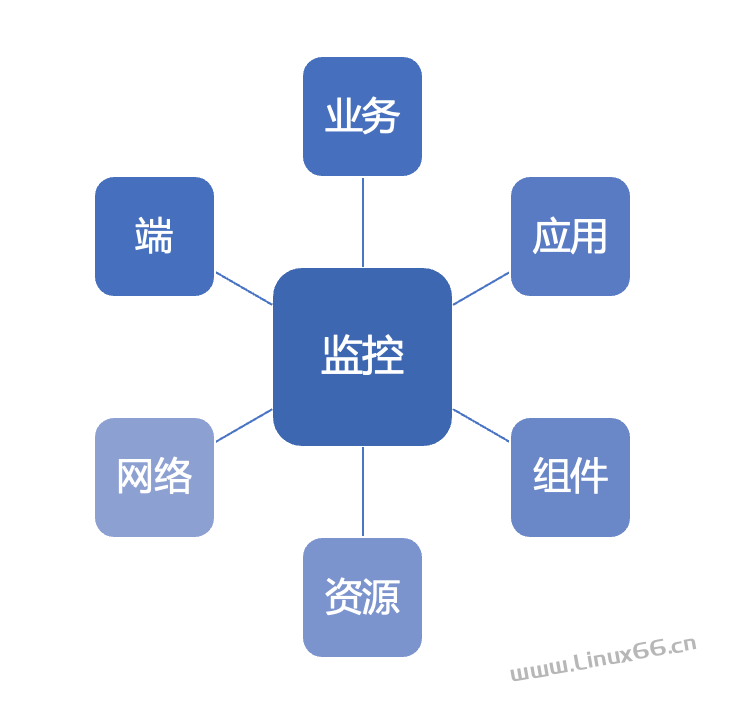
业务监控
业务监控使用业务类指标,比如订单量,平时都是每分钟几百,这会掉底了,说明业务有问题。业务指标/业务监控是最为重要的,体现为:
- 公司高层关注:如果订单掉底,各类 CXO 都会极为关注,相应的产研、运维,显然也要极为重视
- 可以兜底:客户到你们站点的中间环节可能出问题,比如网络、DNS、负载均衡等,这些方面出问题,你的后端模块都是不会告警的,但是订单量这类业务指标可以体现出异常
业务指标数据通常(这里说的通常)从关系库或分析库里读取,通常不会出现在 Zabbix 这类监控工具里,所以,如果你要构建完备的监控系统,要做业务监控,你的告警引擎需要具备读取 OLTP、OLAP 等库的数据并做告警判定的能力。
应用监控
主要是说你们自研/外采的业务系统,通常都是一些 Web 或 RPC 服务,当然,也可能是一些后台批量任务之类的。以 Web 或 RPC 服务举例,业内有一些方法论,典型的是 Google 四个黄金指标和 RED 方法论,即:
- Request:请求量
- Error:错误
- Duration:请求耗时
四个黄金指标比 RED 多了一个 S,即 Saturation,即饱和度,比如你的硬盘 IO 跑满了,新的请求就要在队列里排队,队列深度越大,即饱和度越高,说明越繁忙,需要扩容。
组件监控
这里说的是各类中间件、数据库、分布式存储、Kubernetes 之类的。应用程序通常是依赖这些组件的,这些组件的健康状态直接影响到应用程序的健康状态。所以显然,这些组件也都是要监控的。
这些组件要监控哪些指标才算完备?比较难以回答,可以参考 Google 的四个黄金指标,也可以参考 Datadog 这个文档:https://www.datadoghq.com/blog/monitoring-101-collecting-data/。
其实每个组件要想做好监控,是需要对组件的工作原理极为清楚的,以 MySQL 为例,你可能知道 show global status 可以看到各类系统指标,但是各个指标怎么着算是健康,怎么着算是不健康,这就需要你对 MySQL 的工作原理有深入了解。除了 global status,还有 global variables、InnoDB status、InnoDB metrics、performance schema 等等等等,路漫漫其修远兮。
资源监控
这里是指应用程序的 Runtime 环境,通常是物理机、虚拟机、容器。需要监控 CPU、内存、磁盘、网络等指标。当然,要想做的完备,还需要注意一些偏门指标,比如 ntp 的指标、conntrack 的指标、vmstat 的指标等等。
网络监控
网络监控主要是网络设备、网络链路、外网出口等。
看到网络设备我就头疼 😂,各种 OID 都不一样,之前我们服务 Zenlayer 的时候,感触颇深(Zenlayer 的网络设备种类比较多)。
网络链路通常使用 pingmesh、eBPF 等技术,采集各个单元之间的连通性和连通质量。基础网络如果有问题,上层应用都会有问题,所以要尤为重视。
如果你们的服务是互联网服务,那么外网出口监控、全国各地的拨测监控也是必不可少的。
端监控
端监控是指客户端监控,比如你们的 App、Web 端、H5、小程序,这是用户的访问入口。端监控通常是通过埋点、SDK 等技术采集用户的访问数据,比如页面加载时间、页面交互时间、页面错误率等等。
看吧,搭建了监控系统,只是第一步,连整体进程的 1% 可能都不到,客户在买我们的监控产品之前,我都会跟他讲,监控系统工具和完整的监控体系建设是两码事,只有工具是不够的,后面还有很多落地的工作、消化的过程、治理的工作、甚至运营的工作。
能力完备性
监控这个领域比较驳杂,涉及内容较多,也有很多相关的开源项目,下面我们看看,如何攒一个整体的方案。
数据采集
监控数据通常是指指标数据,可以用 Telegraf、Categraf、Grafana-agent、Datadog-agent、各类 Exporter、Cprobe 等作为采集器。感兴趣的小伙伴可以挨个 Google 一下,这里不展开了。除了指标数据,日志数据也是很重要的监控数据源,业内采集日志的工具也很多,比如 Filebeat、Fluentbit、iLogtail、Loggie 等等。
当然,有些需要监控的数据可能已经存在于 MySQL、Oracle、ClickHouse、Postgres 等库里了,别的同事已经把数据写到这些库里了(典型的比如订单数据),告警引擎直接对接即可,不需要通过某个采集器来做数据采集。
数据存储
指标数据首推 VictoriaMetrics,用 Prometheus 也行,Prometheus 是单点的存储,需要注意一下。
日志存储首推 Elasticsearch,生态好,对于绝大部分中小企业都够用了,当然,你们的量如果特别巨大,需要大几十台 Data Node,也可以尝试 ClickHouse 降低存储成本。如果对日志检索能力没有很高诉求,对成本非常在意,也可以考虑 Loki、OpenObserve 等这类把日志存储到 S3 上的工具。
告警引擎
开源项目里,专门做告警引擎并且兼容各种数据源的,不太好找,Grafana 算一个,但我个人觉得不太好用,Grafana 还是看图能力更强大。夜莺监控也凑合,对兼容 Prometheus 的各类数据源支持的不错,其他数据源支持的有限。日志这块还有个 ElastAlert,专门对 Elasticsearch 的数据做告警的。另外 Clickvisual 主要是对 ClickHouse 的数据做告警。
我个人首推的,是 FlashDuty 的告警引擎。FlashDuty 是我们做一个 SaaS 产品,主要是做告警事件 OnCall,即告警事件收敛降噪、分发、排班、认领升级、协同等。虽然 FlashDuty 是一个 OnCall 产品,却提供了免费的告警引擎,这个告警引擎可以对接 MySQL、Oracle、Postgres、Prometheus、VictoriaMetrics、Loki、ClickHouse 等各类数据源。
这么好?还能免费用?那你们图啥?
你看看,老想着我从你这得到啥,咱们先想如何共赢不好嘛 😄。坦白讲,免费提供告警引擎是为了给大家带来方便,也是为了给 FlashDuty 引流的。最佳白嫖方案是:
注册个 FlashDuty 的免费套餐(发送的短信、电话等数量有限制,毕竟短信、电话啥的运营商是要收费的,我们的斤两还没有能力做慈善),然后就可以白嫖告警引擎了。
如果你们的告警数量很多,有很多人要收电话、短信告警,可以使用 179 元/月·人 的专业套餐,那体验,就非常丝滑了。这就是所谓的引流手段了。量少可以白嫖,量大,让我们也赚点呗,共赢,共赢嘛。
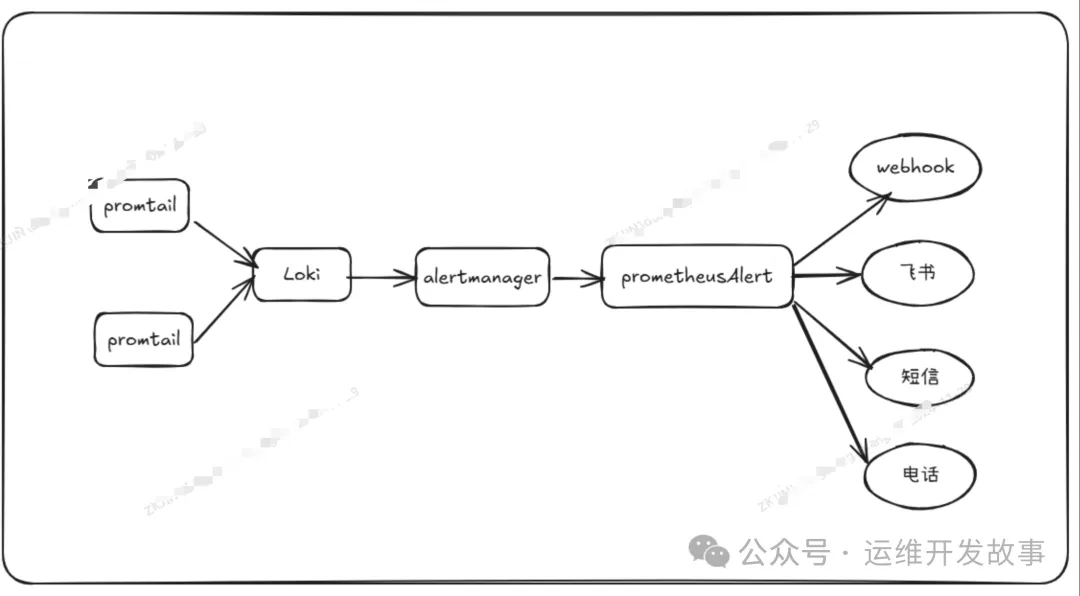
OK,推荐的架构,最终就变成了:
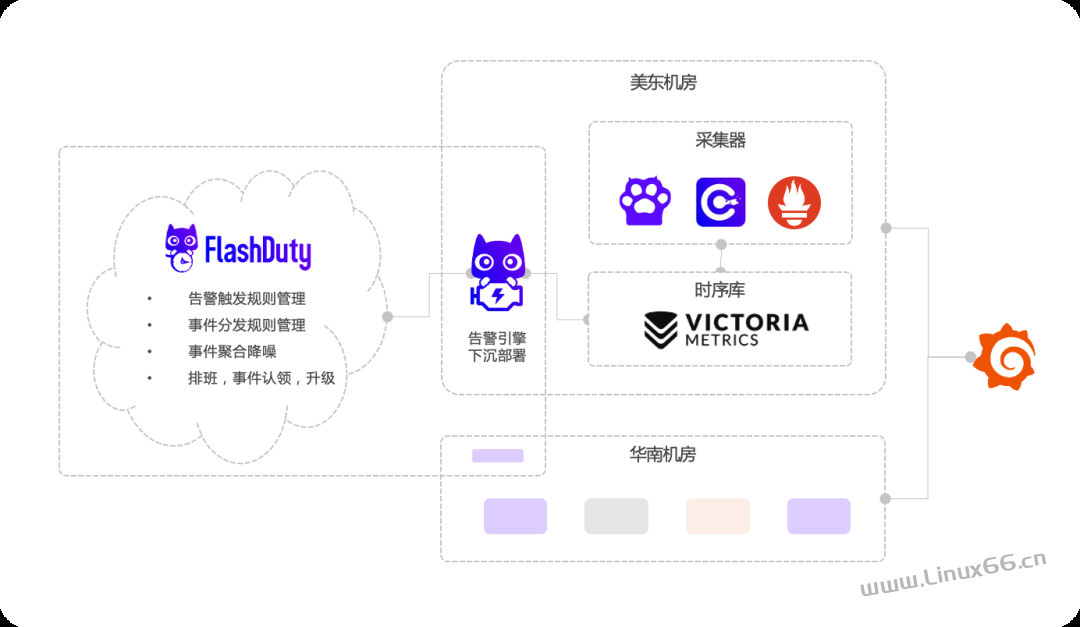
数据采集、存储,还是复用你之前的逻辑,想用 Prometheus 就用 Prometheus,想用 VictoriaMetrics 就用 VictoriaMetrics,日志存在 Loki、Elasticsearch、ClickHouse 等,都行,业务数据用 MySQL 也行,用 Oracle 也行,FlashDuty 的告警引擎都可以对接。
FlashDuty 在云端,访问不了你的存储,所以单独搞了一个 monitedge 的模块,作为告警引擎下沉到你的环境里去部署,monitedge 的逻辑,就是从 SaaS 上同步告警规则,然后读取你的数据做告警判定,如果有异常,生成告警事件推给 SaaS 上的 FlashDuty,非常丝滑。
事件分发
上面讲到的 FlashDuty 就是做事件分发的,国外有 PagerDuty、Opsgenie,都是做 OnCall 事件分发的,FlashDuty 就是对标他们并且适配国内用户习惯。
一般监控系统不是也能做事件分发么?你们开源的夜莺不就可以吗?干嘛还要用 OnCall 工具?
这是因为,一般监控系统侧重在监控数据采集、存储、可视化分析、告警事件生成,对于告警事件后续的处理,比如收敛、降噪、按条件分发、排班、认领、升级、深度集成钉钉飞书企微等,做的功能比较薄,想想 Zabbix、Open-Falcon、Nightingale、Prometheus、ElastAlert、各类云监控,是不是这么个情况?所以 PagerDuty、Opsgenie、FlashDuty 这类产品应运而生。
其实
其实要把监控做好,大概率你的指标数据也就顺便建设的完备了,甚至你的日志也都采集了,其实对于故障定位,也已经可以解决八九成的场景了(可观测性三大支柱,把任意一个支柱单独做到极致,都可以把定位这个事情解决个八九成)。后面如果想继续做可观测性,可以:
- 把缺失的各类数据补充完备
- 做好数据之间的串联
- 根据场景来排布这些数据,把数据真正变成可以洞察的信息
小结
如上,是我接触了 N 多客户之后的一个小感受,分享给大家。如果你对于监控、FlashDuty、可观测性相关的产品感兴趣,欢迎约我们做产品技术交流。