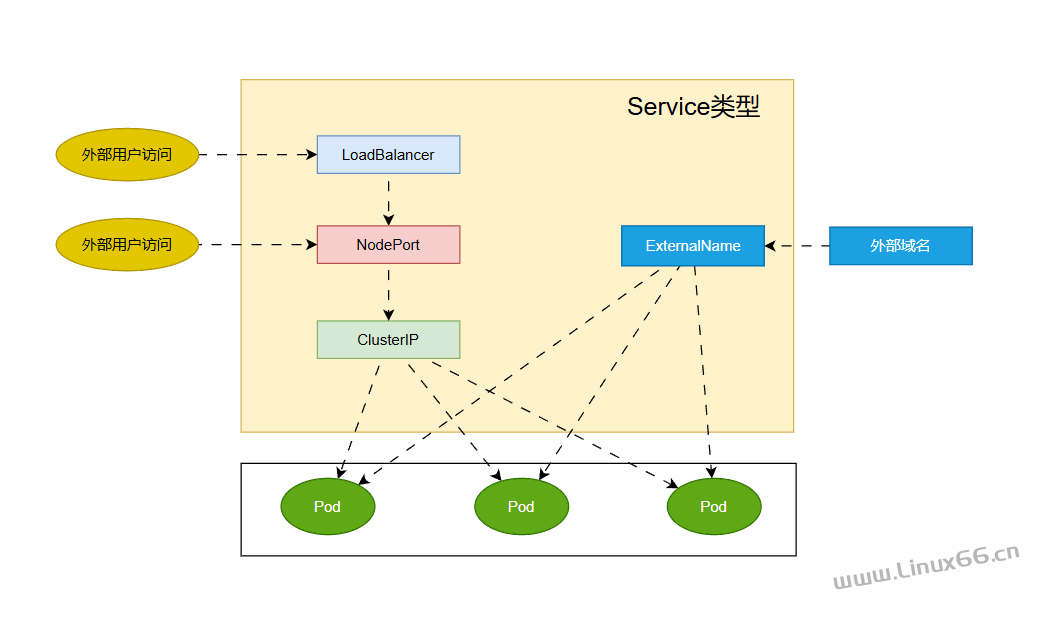
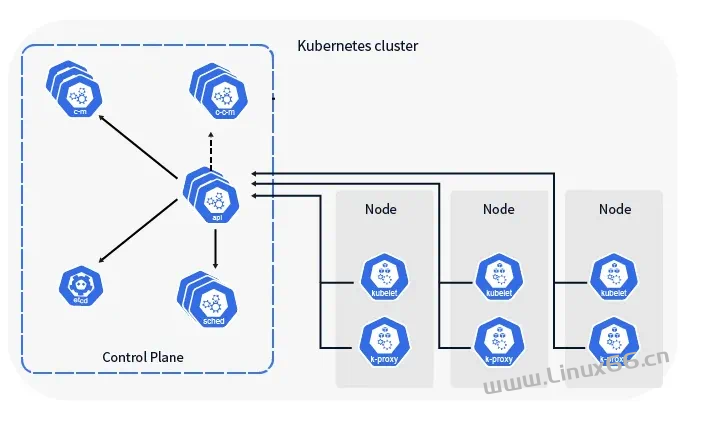
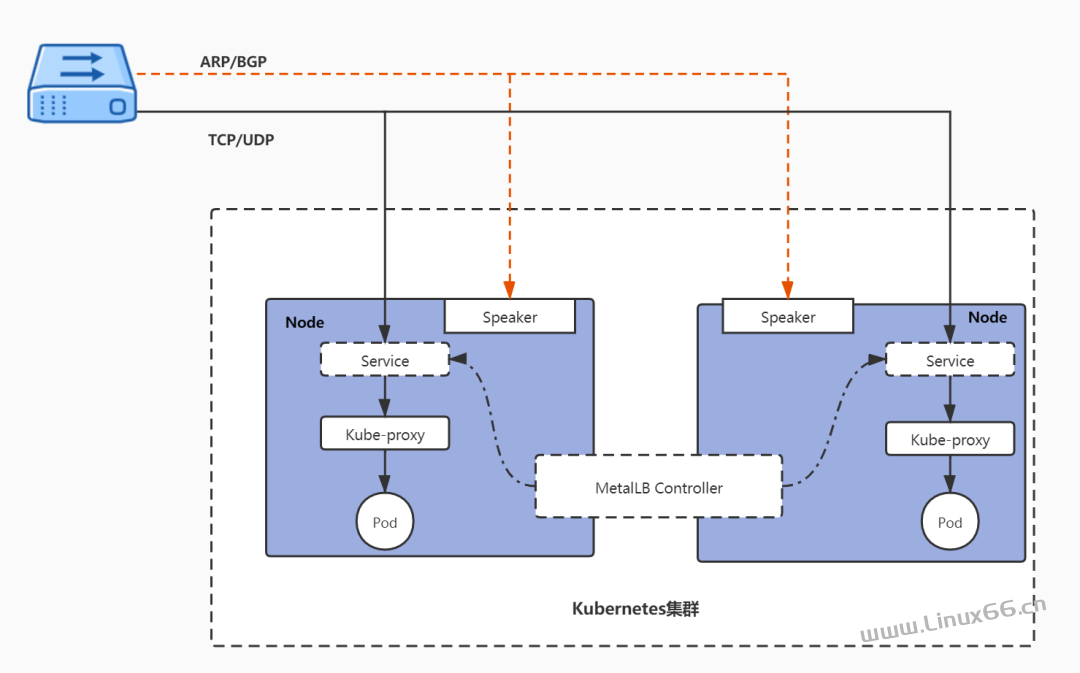
故障应急总让人充满心跳,有时交换机故障、有时光缆被挖断,这次却是机房意外断电。。。
前阵子有个兄弟求助,他们的机房遭遇了意外断电。恢复供电后,k8s集群却无法启动。经过一番“截图分析诊断法”的默契配合,最终成功解决了故障。今天通过这篇文章,和大家分享一下这个过程。
故障发生后,很多指令无法正常回显,容器的元数据也无法正常加载,故障现象主要呈现为如下3点:1. 执行指令的时候会报错couldn't get xxx list。


2. Pod运行时间无法正常获取,出现大量的<Invalid> ago。
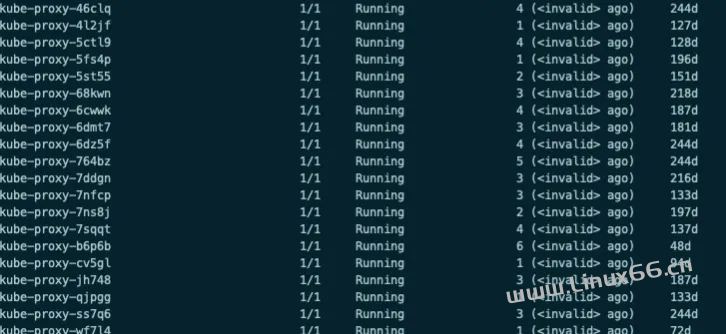
3. 其中一个节点master-6-77的ApiServer Pod创建失败启动

通过上述的现象,一般会初步判断为Etcd或者ApiServer出现故障,由于Etcd的Pod状态是正常,但ApiServer的容器状态异常,所以我们把排查范围暂时锁定在ApiServer上。
首先查询ApiServer Pod的事件日志kubectl describe pod kube-apiserver-k8s-master-6-77 -n kube-system,提示failed to reserve container name xxx: name xxx is reserved for xxx,看样子是容器名冲突了。

从Pod列表中,我们并没有发现重名的Pod,所以可能是断电的时候未能及时释放容器,需要排查底层的容器是否有名称冲突。

在了解到是Containerd容器运行时后,让其在master-6-77这个节点上通过crictl ps -a查看所有的容器,果然发现有冲突的ApiServer容器,但是状态不一样,正是由于其中一个容器的状态为Exited,kubectl才允许新的容器创建,导致这个故障。
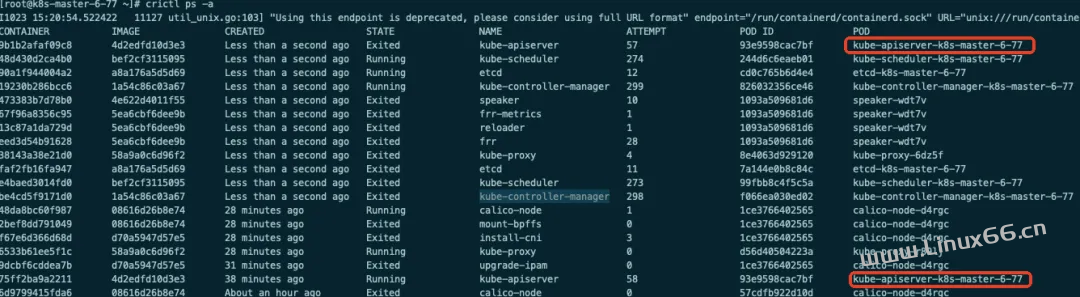
解决的方法其实很简单,把Exited状态的容器删除即可,操作指令如下:
- 将Exited状态的ApiServer容器删除
crictl rm <容器ID>
这个故障影响了集群的自动治愈,让运维人员血液加速,但总算能够快速地解决,并恢复集群的运作,本期分享就到这里,谢谢!
作者: 亦零一
来源:SRE运维手记